


Analytica House
Eyl 4, 2022Robots.txt Nedir? Nasıl Oluşturulur ve Kullanılır?

Arama motoru botları bir web sitesini ziyaret ettiğinde, tarama ve indekslemeyi kontrol etmek için robots.txt dosyasını kullanır. Robots Exclusion Standard olarak da bilinen robots.txt, tarayıcılara web sunucunuzdaki hangi dosyalara, klasörlere veya URL’lere erişip erişemeyeceklerini bildirir.
robots.txt kullanımıyla ilgili birçok yanlış bilgi duyabilirsiniz. Aslında bu dosya, site ziyaretçileri olan botlara hangi URL’leri taramaları gerektiğini söyler. Genellikle istek yükünü azaltmak ve tarama bütçesini optimize etmek için kullanılır. Sayfaların arama sonuçlarında görünmesini engellemez—bunun için etiketi veya bir doğrulama engeli gerekir.
Robots.txt Nedir?
robots.txt, sitenizin kök dizinine yerleştirilen ve tarayıcılara hangi URL’leri (HTTP 200) tarayıp tarayamayacaklarını bildiren basit bir metin dosyasıdır.

Botlar genellikle bu yönergelere uyar. robots.txt dosyasında engellenen sayfalar taranmaz, ancak bu URL’ler başka yerlerde bağlantılıysa Google yine de tarayabilir.
SEO İpucu: Botlar robots.txt dosyanızı okurken 5xx sunucu hatasıyla karşılaşırsa, bir sorun olduğunu varsayar ve taramayı durdurur. Örneğin, bir CDN arkasındaki görseller Google tarafından görünmez hâle gelebilir.
Robots.txt SEO İçin Neden Önemlidir?
Botlar sitemap URL’lerinizi taramadan önce, öncelikle robots.txt dosyanızı çeker. Herhangi bir yanlış yönlendirme, önemli sayfaların atlanmasına yol açabilir. Geçici bir yanlış yapılandırma geri dönüşü olmayan bir durum yaratmamalı—ancak kalıcı zararları önlemek için hızlıca düzeltilmelidir.

Örneğin, yanlışlıkla bir kategori sayfasını engellerseniz, bu yönerge kaldırılana kadar sayfa taranmaz. Botlar robots.txt dosyanızı 24 saat boyunca önbelleğe alır, bu nedenle değişikliklerin etkisi bir güne kadar sürebilir.
Robots.txt Dosyası Nerede Bulunur?
robots.txt dosyanızı sitenizin kök dizinine yerleştirin (örn. example.com/robots.txt). Tarayıcılar evrensel olarak burayı arar—asla taşımayın.
Robots.txt Oluşturma
robots.txt dosyasını herhangi bir metin düzenleyiciyle manuel olarak oluşturabilir veya bir çevrimiçi araçla üretebilirsiniz. Daha sonra sitenizin kök dizinine yükleyin.
Manuel Oluşturma
Basit bir metin düzenleyici açın ve aşağıdaki yönergeleri girin:
User-agent: * Allow: / Sitemap: https://example.com/sitemap.xml
robots.txt olarak kaydedin ve kök dizinine yükleyin.
Önerilen Yönergeler
Önemli robots.txt komutları:
- User-agent: Bir kuralın hangi tarayıcıya uygulanacağını seçer.
- Allow: Tarama izni verir.
- Disallow: Belirtilen yolların taranmasını engeller.
- Sitemap: Tarayıcıları sitemap URL’nize yönlendirir.
User-agent
Hangi botun sonraki kurallara uyacağını belirtir. Yaygın botlar şunlardır:
- Googlebot
- Bingbot
- YandexBot
- DuckDuckBot
- Baiduspider
- …ve daha fazlası.
Örnek: Sadece Googlebot’u teşekkür sayfasından engellemek:
User-agent: Googlebot Disallow: /thank-you
Allow & Disallow
Allow: taramaya izin verir. Yönerge yoksa varsayılan “tümünü izin ver”dir.
Disallow: belirtilen yolun taranmasını engeller.
Örnekler:
- Tümüne izin ver:
User-agent: *
Allow: / - Tümünü engelle:
User-agent: *
Disallow: / - Bir klasörü engelle ama bir alt sayfaya izin ver:
User-agent: * Disallow: /private/ Allow: /private/public-info
Google’un Robots.txt Test Aracı ile Test
Google Search Console’da Index > Coverage altında robots.txt ile ilgili hataları görebilirsiniz. Ayrıca Robots.txt Tester aracını kullanarak Googlebot’un belirli URL’leri nasıl işlediğini simüle edebilirsiniz.
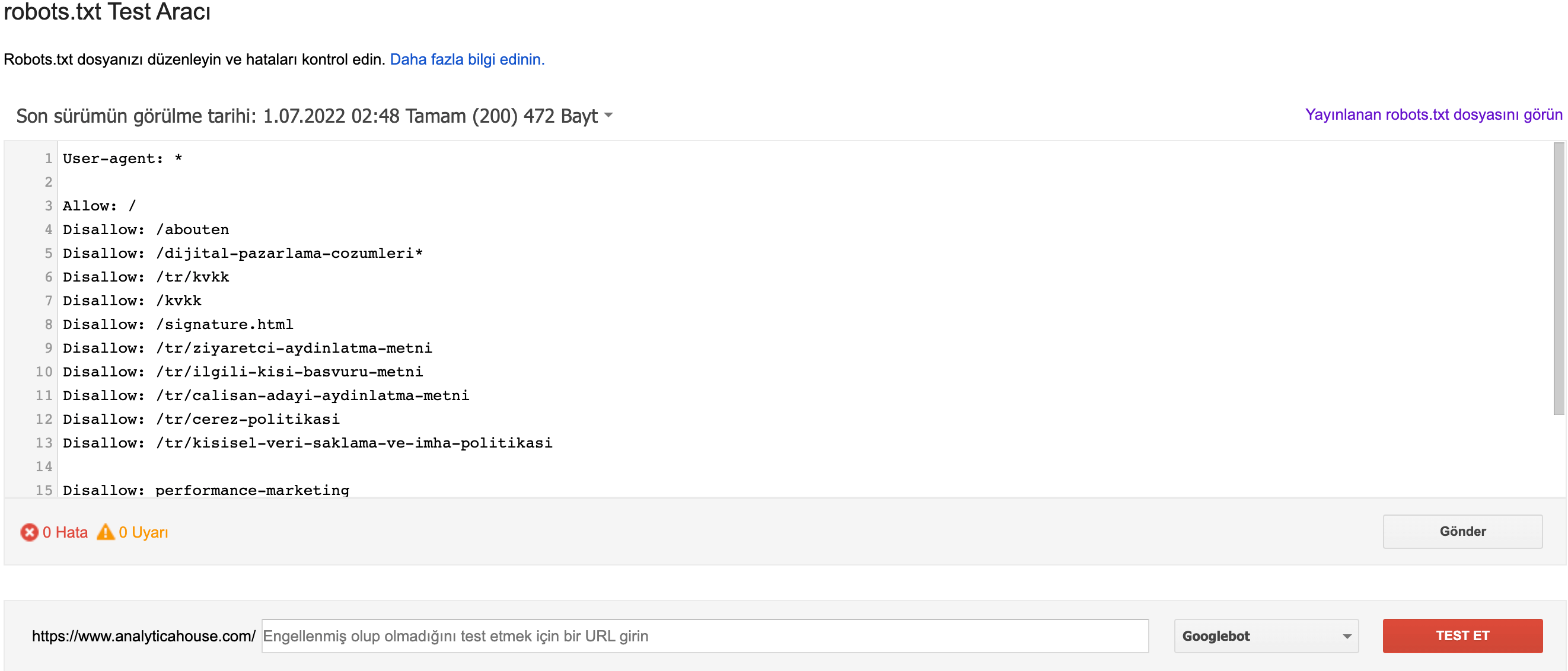
Yaygın GSC Uyarıları
- Blocked by robots.txt: URL engellenmiş.
- Indexed though blocked by robots.txt: Sayfa engellenmiş olmasına rağmen indekslenmiş—
noindexkullanın veya bağlantıları kaldırın.
En İyi Uygulamalar & Hatırlatmalar
- Botlar herhangi bir sayfayı taramadan önce
robots.txtdosyasını çeker. - Low-value sayfaların taranmasını önlemek ve bütçeyi korumak için
Disallow:kullanın. - Sitemap’inizi
Sitemap:ile ekleyin. robots.txtdosyasını 500 KiB altında tutun—Google yalnızca bu boyuta kadar okur.- Sunucu hatalarını test edin—5xx yanıtları botların taramayı durdurmasına neden olur.
- URL yollarında büyük/küçük harf duyarlılığına dikkat edin.
Sonuç
robots.txt, tarayıcıları yönlendirmek ve tarama bütçenizi optimize etmek için basit ama kritik bir dosyadır. Doğru olduğundan emin olun, kök dizinde tutun ve değişiklikleri hemen test edin.
More resources

GEO'nun Altın Kuralı: "Alıntı (Citation)" Sinyallerini Güçlendirmek İçin Taktikler
Dijital pazarlama dünyası, geleneksel arama motoru optimizasyonunun (SEO) ötesine geçerek, Üretken M...
Geleneksel Anahtar Kelimelerden 'Prompt' Optimizasyonuna Geçiş Stratejileri
Dijital pazarlama dünyası, son on yılın en büyük paradigma değişimlerinden birinden geçiyor. Google'...

Anomaly Detection ile Performans Düşüşlerini Erken Yakalamak
Dijital ürünlerde en kritik problemler genellikle en geç fark edilen problemlerdir. Trafik düşer, dö...